Conversational interfaces are a bit of a meme. Every couple of years a shiny new AI development emerges and people in tech go “This is it! The next computing paradigm is here! We’ll only use natural language going forward!”. But then nothing actually changes and we continue using computers the way we always have, until the debate resurfaces a few years later.
We’ve gone through this cycle a couple of times now: Virtual assistants (Siri), smart speakers (Alexa, Google Home), chatbots (“conversational commerce”), AirPods-as-a-platform, and, most recently, large language models.
I’m not entirely sure where this obsession with conversational interfaces comes from. Perhaps it’s a type of anemoia, a nostalgia for a future we saw in StarTrek that never became reality. Or maybe it’s simply that people look at the term “natural language” and think “well, if it’s natural then it must be the logical end state”.
I’m here to tell you that it’s not.
02 Data transfer mechanisms
When people say “natural language” what they mean is written or verbal communication. Natural language is a way to exchange ideas and knowledge between humans. In other words, it’s a data transfer mechanism.
Data transfer mechanisms have two critical factors: speed and lossiness.
Speed determines how quickly data is transferred from the sender to the receiver, while lossiness refers to how accurately the data is transferred. In an ideal state, you want data transfer to happen at maximum speed (instant) and with perfect fidelity (lossless), but these two attributes are often a bit of a trade-off.
Let’s look at how well natural language does on the speed dimension:
The first thing I should note is that these data points are very, verysimplifiedaverages. The important part to take away from this table is not the accuracy of individual numbers, but the overall pattern: We are significantly faster at receiving data (reading, listening) than sending it (writing, speaking). This is why we can listen to podcasts at 2x speed, but not record them at 2x speed.
To put the writing and speaking speeds into perspective, we form thoughts at 1,000-3,000 words per minute. Natural language might be natural, but it’s a bottleneck.
And yet, if you think about your day-to-day interactions with other humans, most communication feels really fast and efficient. That’s because natural language is only one of many data transfer mechanisms available to us.
For example, instead of saying “I think what you just said is a great idea”, I can just give you a thumbs up. Or nod my head. Or simply smile.
Gestures and facial expressions are effectively data compression techniques. They encode information in a more compact, but lossier, form to make it faster and more convenient to transmit.
Natural language is great for data transfer that requires high fidelity (or as a data storage mechanism for async communication), but whenever possible we switch to other modes of communication that are faster and more effortless. Speed and convenience always wins.
My favorite example of truly effortless communication is a memory I have of my grandparents. At the breakfast table, my grandmother never had to ask for the butter – my grandfather always seemed to pass it to her automatically, because after 50+ years of marriage he just sensed that she was about to ask for it. It was like they were communicating telepathically.
*That* is the type of relationship I want to have with my computer!
03 Human Computer Interaction
Similar to human-to-human communication, there are different data transfer mechanisms to exchange information between humans and computers. In the early days of computing, users interacted with computers through a command line. These text-based commands were effectively a natural language interface, but required precise syntax and a deep understanding of the system.
The introduction of the GUI primarily solved a discovery problem: Instead of having to memorize exact text commands, you could now navigate and perform tasks through visual elements like menus and buttons. This didn’t just make things easier to discover, but also more convenient: It’s faster to click a button than to type a long text command.
Today, we live in a productivity equilibrium that combines graphical interfaces with keyboard-based commands.
We still use our mouse to navigate and tell our computers what to do next, but routine actions are typically communicated in form of quick-fire keyboard presses: ⌘b to format text as bold, ⌘t to open a new tab, ⌘c/v to quickly copy things from one place to another, etc.
These shortcuts are not natural language though. They are another form of data compression. Like a thumbs up or a nod, they help us to communicate faster.
Modern productivity tools take these data compression shortcuts to the next level. In tools like Linear, Raycast or Superhuman every single command is just a keystroke away. Once you’ve built the muscle memory, the data input feels completely effortless. It’s almost like being handed the butter at the breakfast table without having to ask for it.
Touch-based interfaces are considered the third pivotal milestone in the evolution of human computer interaction, but they have always been more of an augmentation of desktop computing rather than a replacement for it. Smartphones are great for “away from keyboard” workflows, but important productivity work still happens on desktop.
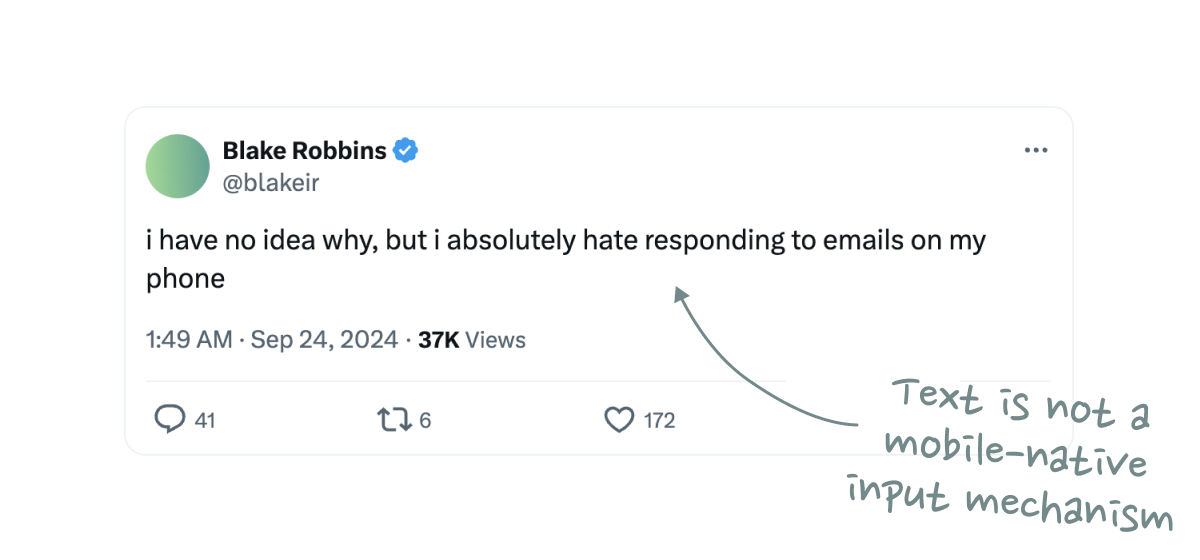
That’s because text is not a mobile-native input mechanism. A physical keyboard can feel like a natural extension of your mind and body, but typing on a phone is always a little awkward – and it shows in data transfer speeds: Average typing speeds on mobile are just 36 words-per-minute, notably slower than the ~60 words-per-minute on desktop.
We’ve been able to replace natural language with mobile-specific data compression algorithms like emojis or Snapchat selfies, but we’ve never found a mobile equivalent for keyboard shortcuts. Guess why we still don’t have a truly mobile-first productivity app after almost 20 years since the introduction of the iPhone?
“But what about speech-to-text,” you might say, pointing to reports about increasing usage of voice messaging. It’s true that speaking (150wpm) is indeed a faster data transfer mechanism than typing (60wpm), but that doesn’t automatically make it a better method to interact with computers.
We keep telling ourselves that previous voice interfaces like Alexa or Siri didn’t succeed because the underlying AI wasn’t smart enough, but that’s only half of the story. The core problem was never the quality of the output function, but the inconvenience of the input function: A natural language prompt like “Hey Google, what’s the weather in San Francisco today?” just takes 10x longer than simply tapping the weather app on your homescreen.
LLMs don’t solve this problem. The quality of their output is improving at an astonishing rate, but the input modality is a step backwards from what we already have. Why should I have to describe my desired action using natural language, when I could simply press a button or keyboard shortcut? Just pass me the goddamn butter.
04 Conversational UI as Augmentation
None of this is to say that LLMs aren’t great. I love LLMs. I use them all the time. In fact, I wrote this very essay with the help of an LLM.
Instead of drafting a first version with pen and paper (my preferred writing tools), I spent an entire hour walking outside, talking to ChatGPT in Advanced Voice Mode. We went through all the fuzzy ideas in my head, clarified and organized them, explored some additional talking points, and eventually pulled everything together into a first outline.
This wasn’t just a one-sided “Hey, can you write a few paragraphs about x” prompt. It felt like a genuine, in-depth conversation and exchange of ideas with a true thought partner. Even weeks later, I’m still amazed at how well it worked. It was one of those rare, magical moments where software makes you feel like you’re living in the future.
In contrast to typical human-to-computer commands, however, this workflow is not defined by speed. Like writing, my ChatGPT conversation is a thinking process – not an interaction that happens post-thought.
It should also be noted that ChatGPT does not substitute any existing software workflows in this example. It’s a completely new use case.
This brings me to my core thesis: The inconvenience and inferior data transfer speeds of conversational interfaces make them an unlikely replacement for existing computing paradigms – but what if they complement them?
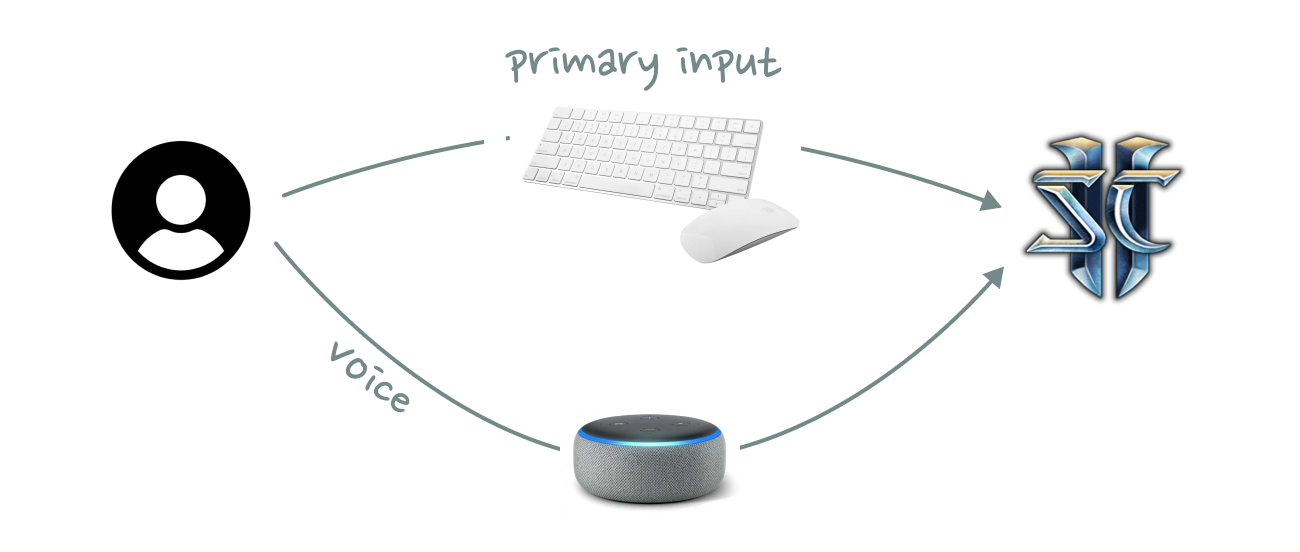
The most convincing conversational UI I have seen to date was at a hackathon where a team turned Amazon Alexa into an in-game voice assistant for StarCraft II. Rather than replacing mouse and keyboard, voice acted as an additional input mechanism. It increased the bandwidth of the data transfer.
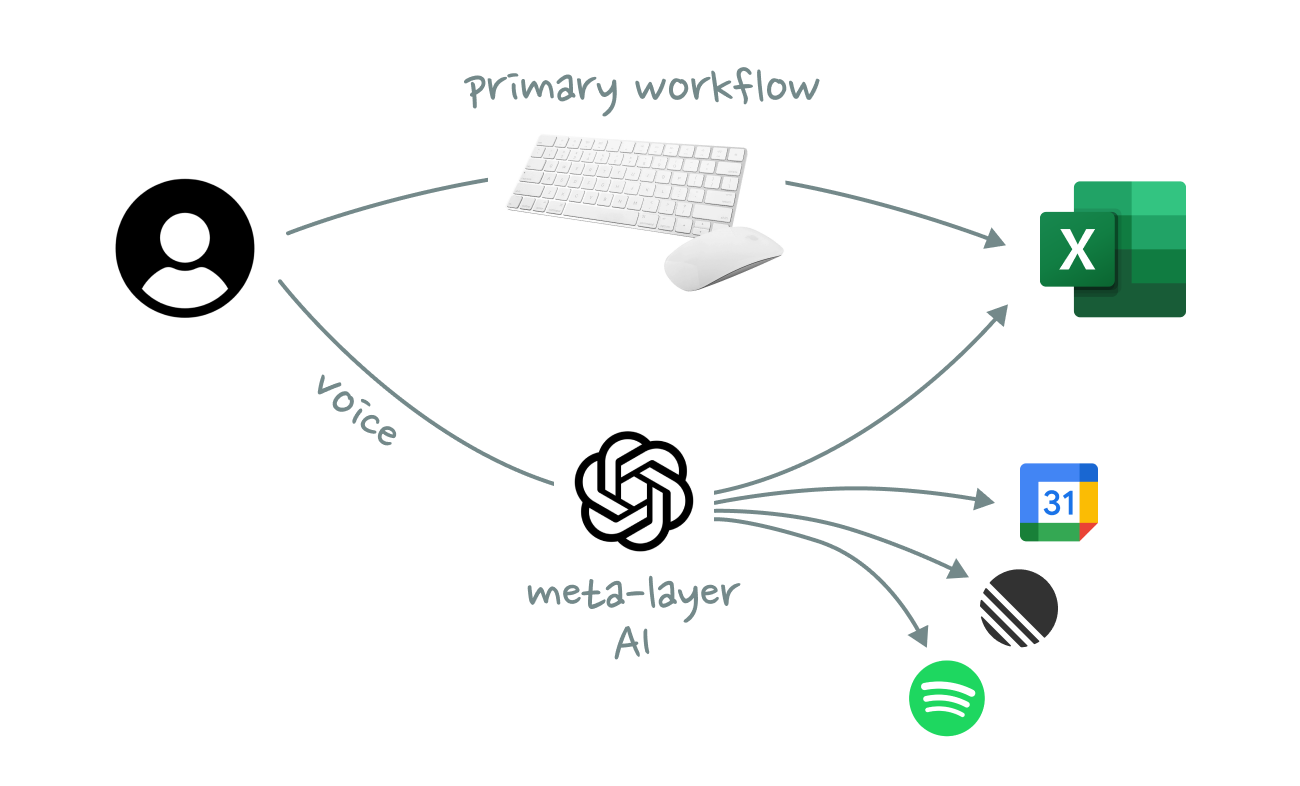
You could see the same pattern work for any type of knowledge work, where voice commands are available while you are busy doing other things. We will not replace Figma, Notion, or Excel with a chat interface. It’s not going to happen. Neither will we forever continue the status quo, where we constantly have to switch back and forth between these tools and an LLM.
Instead, AI should function as an always-on command meta-layer that spans across all tools. Users should be able to trigger actions from anywhere with simple voice prompts without having to interrupt whatever they are currently doing with mouse and keyboard.
For this future to become an actual reality, AI needs to work at the OS level. It’s not meant to be an interface for a single tool, but an interface across tools. Kevin Kwok famously wrote that “productivity and collaboration shouldn’t be two separate workflows”. And while he was referring to human-to-human collaboration, the statement is even more true in a world of human-to-AI collaboration, where the lines between productivity and coordination are becoming increasingly more blurry.
The second thing we need to figure out is how we can compress voice input to make it faster to transmit. What’s the voice equivalent of a thumbs-up or a keyboard shortcut? Can I prompt Claude faster with simple sounds and whistles? Should ChatGPT have access to my camera so it can change its answers in realtime based on my facial expressions?
Even as a secondary interface, speed and convenience is all that matters.
05 Closing thoughts
I admit that the title of this essay is a bit misleading (made you click though, didn’t it?). This isn’t really a case against conversational interfaces, it’s a case against zero-sum thinking.
We spend too much time thinking about AI as a substitute (for interfaces, workflows, and jobs) and too little time about AI as a complement. Progress rarely follows a simple path of replacement. It unlocks new, previously unimaginable things rather than merely displacing what came before.
The same is true here. The future isn’t about replacing existing computing paradigms with chat interfaces, but about enhancing them to make human-computer interaction feel effortless – like the silent exchange of butter at a well-worn breakfast table.
Thanks to Blake Robbins, Chris Paik, Jackson Dahl, Johannes Schickling, Jordan Singer, and signüll for reading drafts of this post.
Time is a curious thing. It’s a constantly flowing stream that can’t be paused, stopped, or repeated. We experience it, but we can’t control it. We can’t even touch or feel it.
To get a better grasp of this weird, intangible resource that governs everything around us, humanity has invented a variety of “time devices”. These devices help us to plan and optimize how we spend our time. To make the most out of the here and now.
The most popular time device is the watch. A watch is a useful tool, but its functionality is limited to the present moment. It allows us to see time, but not to manage it. It only tells us the status quo.
Calendars, on the other hand, cover the entire spectrum of time. Past, present and future. They are the closest thing we have to a time machine. Calendars allow us to travel forward in time and see the future.More importantly, they allow us to change the future.
Changing the future means dedicating time to things that matter. It means allocating our most precious resource to activities with the highest expected return on investment.
You would expect technologists and entrepreneurs to be intensely focused on perfecting such a magical time travel device, but surprisingly, that has not been the case. Our digital calendars turned out to be just marginally better than their pen and paper predecessors. And since their release, neither Outlook nor Google Calendar have really changed in any meaningful way.
Isn’t it ironic that, of all things, it’s our time machines that are stuck in the past?
The essay at hand is an exploration of what calendars could be if they weren’t stuck in time. But before we discuss their future, we first need to analyze their present status and how they fit into the rest of the productivity stack.
02 Calendars and the productivity stack
Our productivity stack consists of four types of tools:
Note-taking apps To document and organize our thoughts
Email To communicate with others
Task managers To organize the things we need to get done
Calendars To manage our time
The fact that we use four distinct tools suggests that note-taking, email, task management, and time management are four distinct activities. But when you look closer, you’ll realize that these activities are actually not that clear-cut. In fact, they all heavily overlap. Notes are just emails to your future self. Emails are just tasks. And tasks are just calendar events.
My personal workflow looks like this:
I treat my email inbox as my primary task manager (and note-taking tool).
Tasks are emails I receive from others or emails I send to myself.
I snooze emails until the week I want to get them done.
At the beginning of each week, I go through my email todo list and block time in my calendar for each task.
The email<>todo part of this workflow actually works reasonably well. Most of today’s email clients are built around the concept of Inbox Zero, which effectively turns your email inbox into a todo list with public write access.
The part we haven’t really figured out yet is the intersection between task managers and calendars.
Treating todos as calendar events is helpful because calendars introduce constraints. A calendar forces you to estimate how long each task will take and then find empty space for it on a 24 hours × 7 days grid, which is already cluttered with other things. It’s like playing Tetris with blocks of time.
So how do we get tasks into our calendars without awkwardly switching back and forth between two different apps that don’t talk to each other?
New productivity tools such as Amie are trying to solve this problem by natively inserting todo lists into the calendar experience. In Amie, every calendar event is a task that can be marked as done.
This approach is a step in the right direction, but it doesn’t go far enough. I agree that tasks should live in your calendar, but that doesn’t mean every calendar event should be a task. The way I see it, tasks are just one of many different types of calendar events. And just one of many different calendar layers.
03 Managing time in three dimensions
To make the concept of calendar layers a little more tangible, let’s look at a scenario that you have probably seen before:
What’s happening here?
1. You have a meeting with Mike A meeting is a multiplayer calendar event. It is not the same as a task. It is simply a reminder for all meeting participants that their presence is required (or desired) at a specific time and place. There is no “to do” here apart from showing up on time.
2. You need to travel to and back from your meeting To ensure that no other meetings are scheduled during those travel times, you added two “do not schedule” blocks (DNS). These are neither meetings nor tasks. Their only purpose is to avoid conflicts with other upcoming events.
The DNS blocks appear before and after the meeting, but what they really represent is one entire layer of time that stretches from 10:30 to 12:30. Your conversation with Mike is a meeting layeron top of your blocked time layer.
We tend to think of calendars as 2D grids with mutually exclusive blocks of time, but as this example shows, not all events automatically cancel each other out. Depending on their characteristics, they can be layered on top of each other. This means we manage time in three, not two, dimensions.
Let’s see if we can add another layer to the mix.
As discussed at the start of this chapter, neither blocked time nor meetings qualify as tasks — but what about talking points or agenda items that need to be covered in your meeting?
We are now looking at three different types of calendar events, each with their own unique set of properties. The problem is that our calendars treat all of these different events equally. They don’t natively differentiate between a task and a meeting even though they are two completely different things.
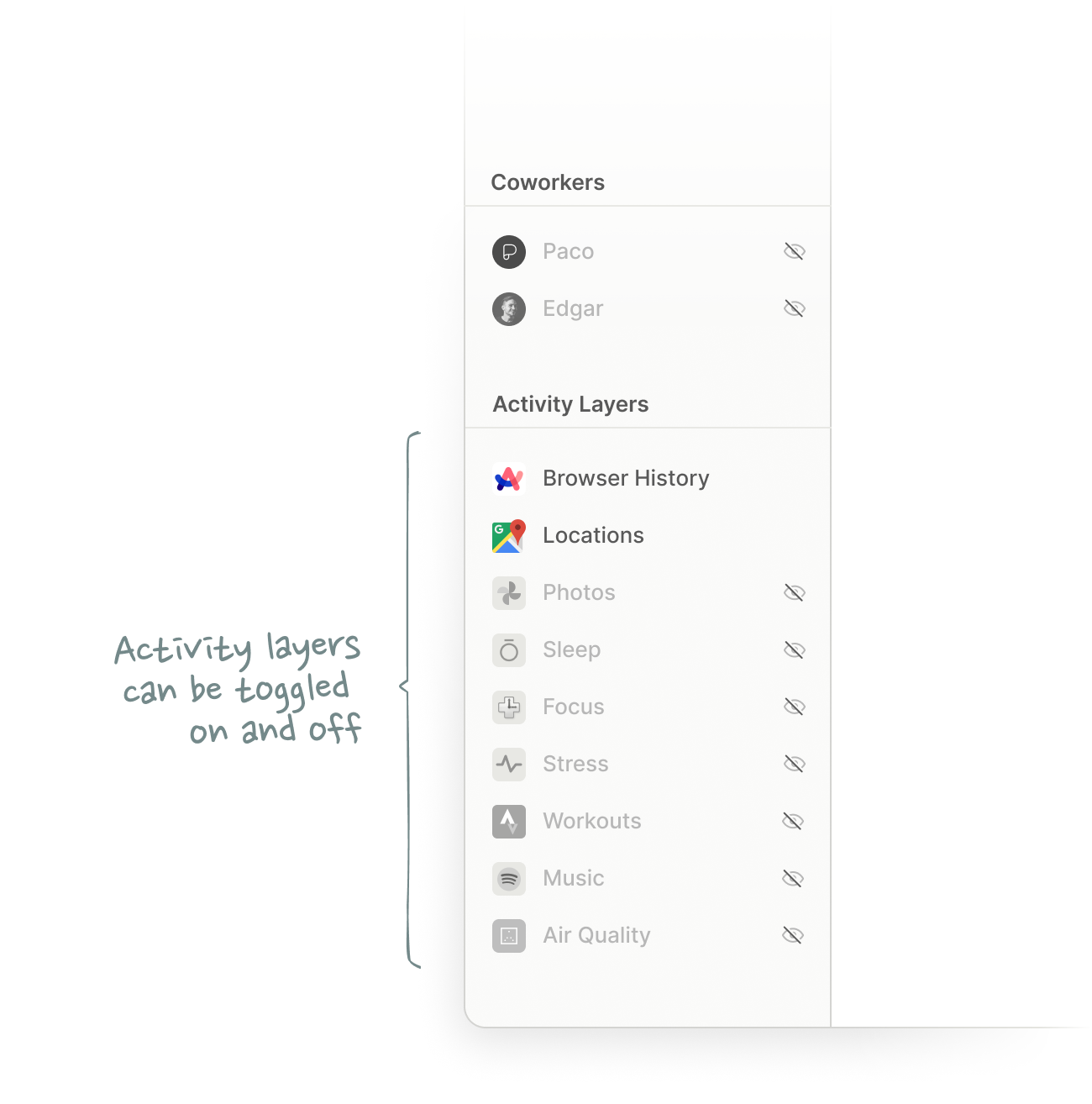
When I chatted with Cron founder Raphael Schaad about this issue, he pointed out another missing layer: Activities. An activity takes place for a prolonged period of time, but only requires your attention at certain points of it — not throughout.
Flights, for example, should be native calendar objects with their own unique attributes to highlight key moments such as boarding times or possible delays.
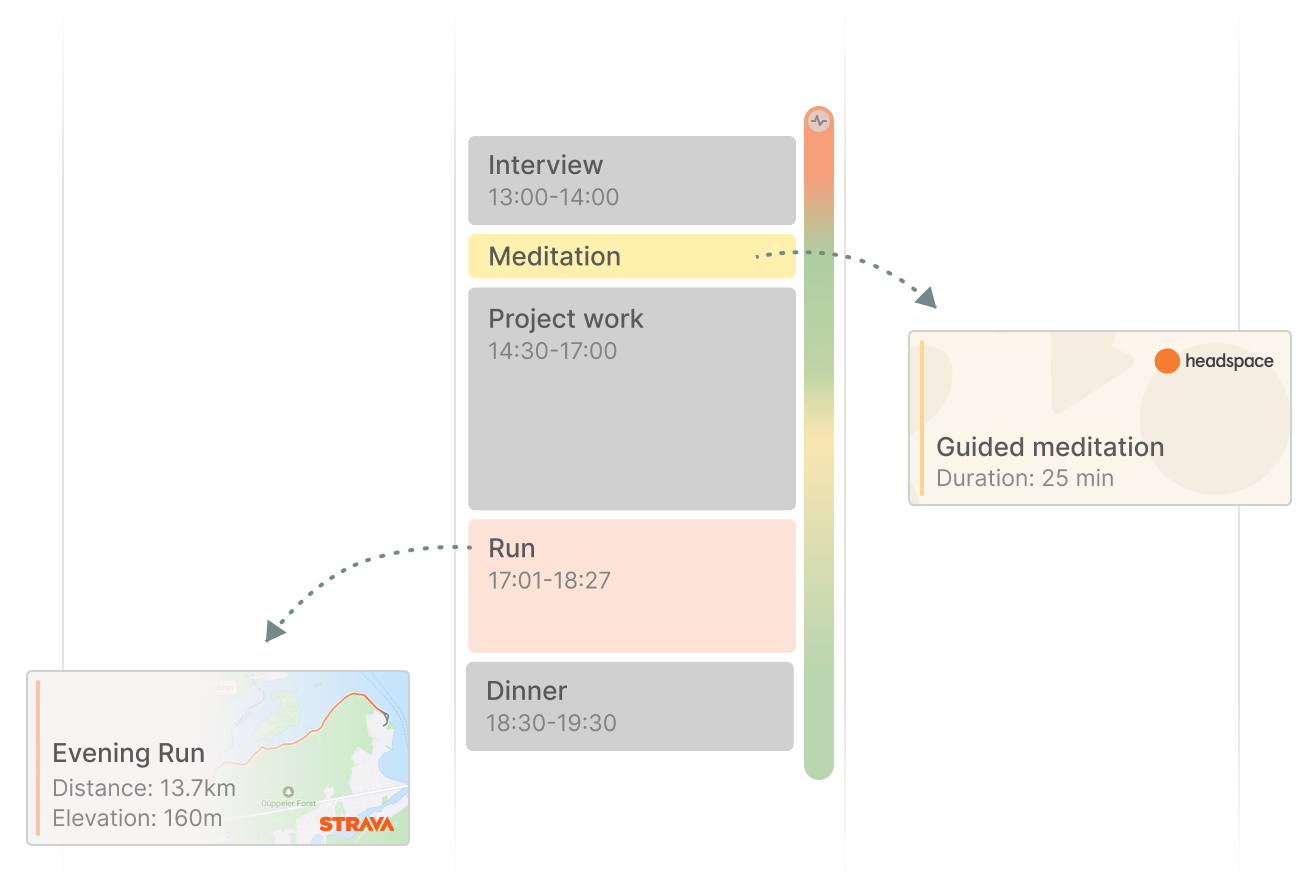
This gets us to an interesting question: If our calendars were able to support other types of calendar activities, what else could we map onto them?
What’s so interesting about this idea is not just that it introduces another unique calendar layer, but that the data of this layer is rooted in the past. In contrast to traditional calendar events, all of these Spotify entries were created after they happened.
Something I never really noticed before is that we only use our calendars to look forward in time, never to reflect on things that happened in the past. That feels like a missed opportunity.
While a Spotify layer might seem more like a gimmick than a meaningful productivity hack, the idea of visualizing data from other applications in form of calendar events feels incredibly powerful. What if I could see health data alongside my work activities, for example?
My biggest gripe with almost all quantified self tools is that they are input-only devices. They are able to collect data, but unable to return any meaningful output. My Garmin watch can tell my current level of stress based on my heart-rate variability, but not what has caused that stress or how I can prevent it in the future. It lacks context.
Once I view the data alongside other events, however, things start to make more sense. Adding workouts or meditation sessions, for example, would give me even more context to understand (and manage) stress.
Sleep is another data layer that would make a lot more sense in my calendar than in a standalone app. I already block time in my calendar for sleep (mostly as a DNS-memo to coworkers in other time zones), so why not add sleep quality data directly to that calendar event?
This way I could plan my day ahead with a lot more accuracy. Fully recharged after a solid eight hours of sleep? Block more focus time. Lack of deep sleep? Add another coffee break to the agenda.
This example is particularly interesting because it leverages all of our calendar’s time travel capabilities. It allows us to shape the future by studying the past.
Once you start to see the calendar as a time machine that covers more than just future plans, you’ll realize that almost any activity could live in your calendar. As long as it has a time dimension, it can be visualized as a native calendar layer.
Most of these data layers are pretty meaningless in isolation; it’s only when we view them alongside each other that they unlock their value. Even a Spotify layer starts to make sense when you look at it in combination with stress data (which music calms me down?), productivity metrics (which music helps me focus?), or personal activities from the past (nostalgia).
05 Closing thoughts
The takeaway of this essay is twofold:
Calendars should natively differentiate between different types of calendar events. Tasks, meetings, blocked time, and other activities should look and behave differently depending on their respective attributes.
This would open the door for a virtually infinite amount of other use cases that could be integrated into the calendar experience in the form of unique calendar layers.
These changes would not just make the calendar a stronger center of gravity in the aforementioned productivity stack, but turn into an actual tool for thought, where time serves as the scaffolding for our future plans and our memory palaces of the past.
The world’s most successful companies all exhibit some form of structural competitive advantage: A defensibility mechanism that protects their margins and profits from competitors over long periods of time. Business strategy books like to refer to these competitive advantages as “economic moats”.
One of the most citedtypesofmoats is the concept of network effects. Network effects occur when the value of a product or service is subject to the number of users. A positive network effect means that a product or service becomes more valuable to its users as more people use it.
Network effects are extremely hyped and have become a bit of a meme in recent years among tech entrepreneurs, investors and policy makers. The five largest companies by market cap in the US all seem to be built on some sort of network effect and some even go so far as to claim that 70% of tech value creation since 1994 is predicated on network effects.
While network effects can indeed be very powerful, they are also one of the most misunderstood – and in many cases overrated – concepts in business strategy. Not all network effects are created equal and the most successful ones are just a means to an end.
This essay isn’t about network effects per se. It’s about the end state that they can enable: Defaults. In the next few chapters I’ll teach you how to think in layers, explain why defensibility is really about real estate, and tell you what Salesforce and Jesus have in common (got your attention now, don’t I?).
Let’s get started.
02 Theory Primer
Before we dive into it, let’s start with a super quick theory primer on network effects.
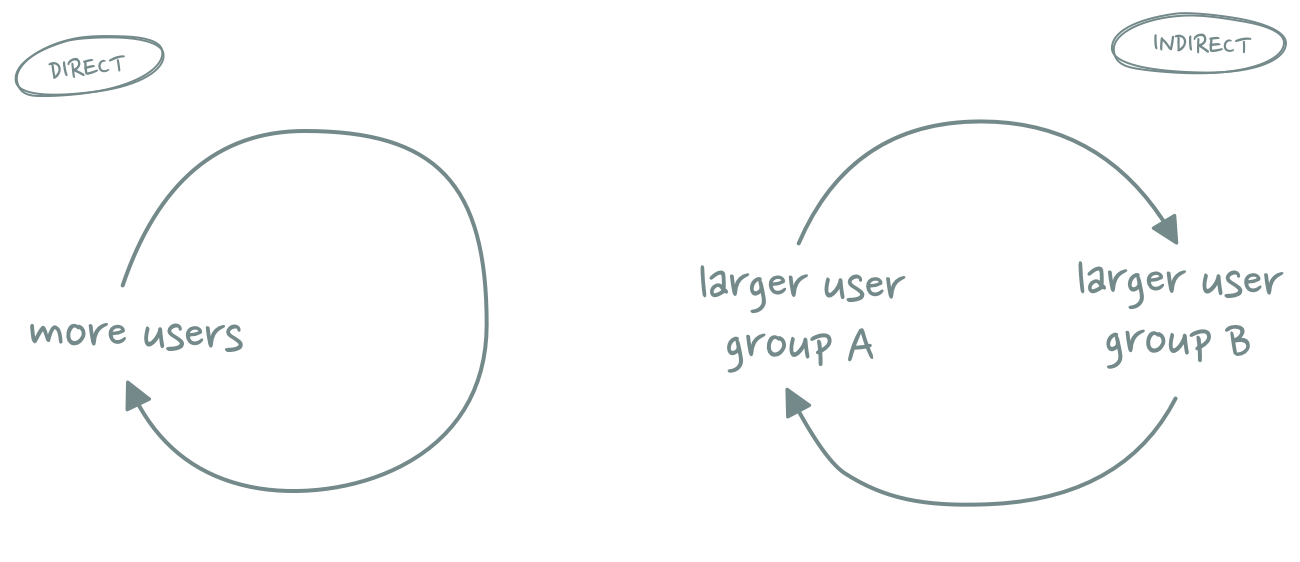
Network effects can be broadly divided into three different categories: Direct, indirect and data network effects.
Direct network effects – as the name suggests – occur when the number of users has a direct impact on the value of a product. A telephone, for example, is worthless if you are the only person who owns one. But with every additional user who joins the telephone network, the number of people you can have a conversation with goes up and therefore the overall value of a telephone increases. The same dynamic is true for chat apps, social networks and p2p payment systems.
Indirect network effects are a little more complicated. They occur in two-sided (or multi-sided) products where the size of one user group affects how valuable the product is to another user group. Operating systems are an often cited example here: The more users an OS has, the more attractive it becomes for developers. More developers and apps, on the other hand, make the platform more valuable for users, thereby generating a positive feedback loop between the two sides.
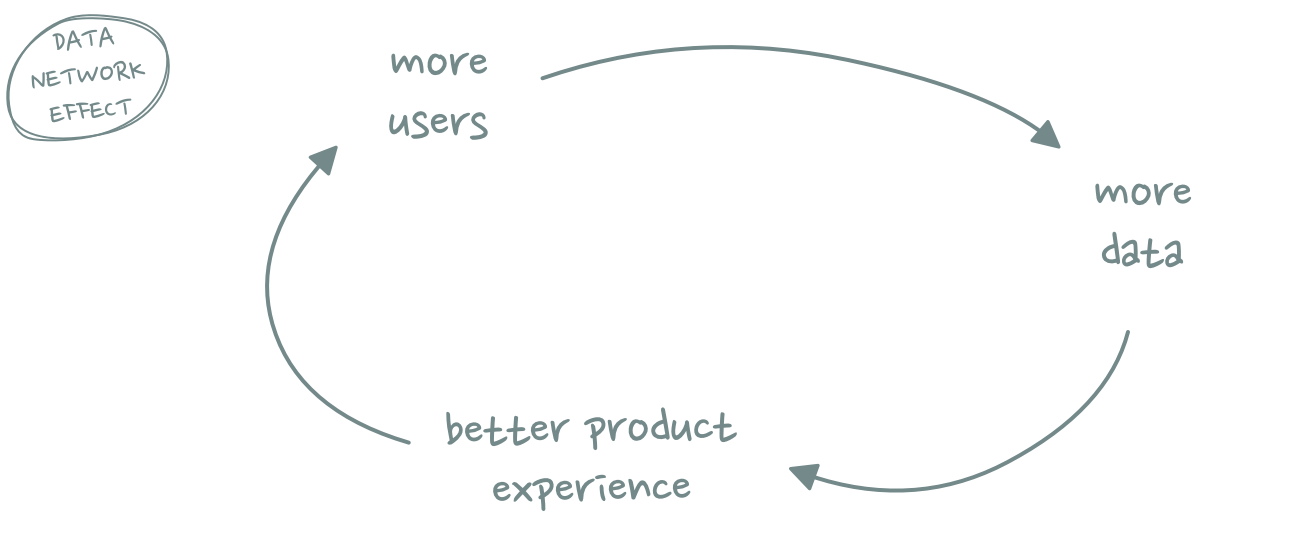
The third category, data network effects, describes products which become better with more users via the data those users generate. Waze is a popular example of this category as are products that are powered by machine learning. More users lead to more data which lead to better recommendations or predictions and, thus, a better user experience.
There are two other concepts I would like to briefly introduce you to: Switching costs and multihoming costs. Switching costs describe how difficult or expensive it is for a user to switch from one product to another, whereas multihoming costs explain how easy or likely it is to use multiple competing networks simultaneously.
Both of these costs are not necessarily monetary – they can also be psychological or time/effort-based. The higher the switching and multihoming costs, the more defensible a network typically becomes.
What gets people so excited (or worried) about network effects is not just their defensibility though. It’s the idea of reinforcing feedback loops and the resulting exponential growth that they enable. As any paper or blog post about the topic will point out, network effects create winner-take-all-dynamics where only one or two firms end up dominating an entire industry and can’t be challenged.
But is that actually true?
03 Are Network Effects Overrated?
I have studied multiple network effect businesses for this essay and two things struck me.
First of all, it feels like many of the prototypical network effect companies are not as defensible as the literature suggests.
Today, Facebook is seen as the prime example for the power of network effects – and yet, one wonders where Facebook would be had it not acquired Instagram back in 2012. People also seem to forget about all the other social apps which Facebook has bought and subsequently shut down over the years. Why would a company that has supposedly “won the market” spend hundreds of millions of dollars to acquire smaller competitors?
Facebook and Instagram are also hardly the only social networks out there. Twitter, Reddit, YouTube, TikTok et al. all seem to be doing just fine. Are there no winner-take-all dynamics in social?
There is a similar pattern for chat apps: WhatsApp, iMessage, Telegram, Facebook Messenger and Snapchat all have at least 100 million users. Why doesn’t the market tip in favor of one or two of them as the literature suggests? Looking at the speed at which some of these apps have grown, one has to ask if network effects don’t perhaps have the exact opposite effect: Maybe they are not a defensibility mechanism for incumbents but a growth mechanism for new market entrants?
Another often cited network effect example is Google Search. Data network effects have made Google the best search engine on the planet. With each additional search query, Google’s algorithms become a little bit smarter and its search results better – which in turn attracts even more users and usage. This positive feedback loop makes Google unstoppable … and yet, Google pays Apple $15bn per year to remain the default search engine on iOS. Isn’t this a bit of a narrative violation?
Now, I’m not arguing that Facebook and Google aren’t extremely powerful companies. They clearly are. But I’m not convinced that their power is really based on network effects. Network effects might have helped them to get to where they are today, but their defensibility lies somewhere else.
×××
The second thing that I found interesting hit me when I looked at examples of industries that had indeed achieved winner-take-all (or winner-take-most) dynamics:
Telephone
Railroads
VHS
Smartphones
QWERTY keyboards
If you study the list closely, you’ll notice that these businesses all have something in common. Something that the before-mentioned industries don’t have. They are based on atoms, not just bits.
Why is that important?
In contrast to bits, atoms have marginal costs. You can copy and paste a piece of software at virtually zero cost, but producing an additional piece of hardware has all sorts of marginal costs associated with it (material, production, shipping, …). This means that atom-based network effect businesses have switching and multihoming costs.
If you want to switch from Android to iOS (or use both OSs simultaneously) you have to spend at least a few hundred dollars on a new iPhone. Software, on the other hand, is typically free to use, so switching to a new chat app, social network or search engine doesn’t come with a real price tag. Because of their marginal costs, atom-based businesses have a greater lock-in effect and thus defensibility.
Another under-appreciated aspect that makesmultihoming less likely is that atom-based products have physical space constraints. You can’t have eight competing rail road networks because there simply isn’t enough real estate to build them. Similarly, most consumers wouldn’t be willing to carry around more than one smartphone with them. Your pockets also have limited real estate.
Software businesses don’t face this type of scarcity. You can install as many apps on your phone as you want. Bits make multihoming less expensive and less inconvenient.
So does that mean that network effects are only an effective moat for atom-based products and services?
Not quite, but you’ll see why the bits vs atoms distinction matters once you start to think in layers.
04 Thinking in Layers
You may have heard about the concept of “value chains” before. Value chains are horizontal visualizations of all the value-adding business activities involved in creating a product or service from start to finish. They are great to analyze traditional businesses and industries but they are not a very useful framework for tech companies.
If you want to understand the power dynamics between different platforms, aggregators and other players in a tech ecosystem, it’s better to look at them as a vertical stack with different layers.
On each layer of the stack, companies are trying to create value and to capture value. The lowest layers of the stack are typically the most powerful. If you are able to take control of a layer, you can dictate the terms of most of the value creation and value capture that is happening in the layers above you.
As a result, you see companies trying to
create layers on top of their business (everyone wants to be a platform)
move down the stack to get closer to the base layer (to increase defensibility)
What is the base layer?
The base layer is the final interface between the stack and the end user – which is typically an operating system tied to a piece of hardware. This is why atom-based network effects are so powerful: They help companies gain control of the most powerful layer of the stack.
Let’s work through a few examples to make this concept a little more tangible.
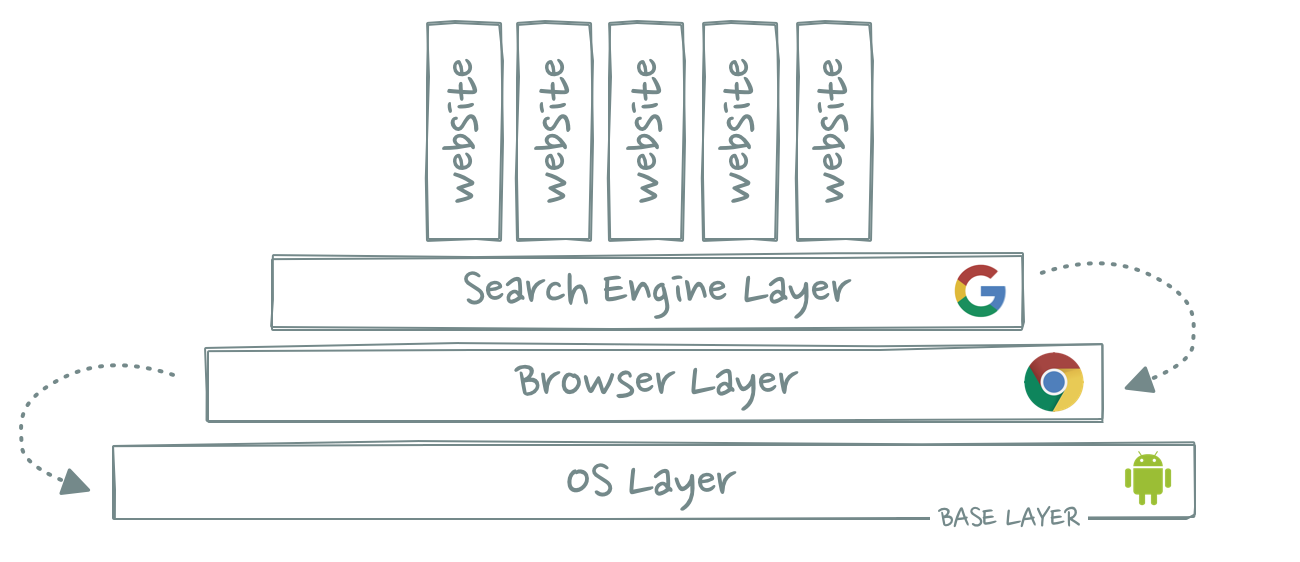
05 The Google Stack
Google started as a simple website that allowed users to search other websites. Thanks to the superiority of its PageRank algorithm, more and more users started using Google Search, resulting in better search results and thus in even more users switching over to Google Search.
Thanks to this powerful data network effect, Google was able to move down the stack. Google wasn’t “just a website” anymore, it became an aggregator that commoditized all other websites and made them layers on top of Google’s.
The data network effect, however, is not the real moat here. It’s just a means to an end. The end goal is to become a default on the layer below.
Let’s go back to atom-based network effects real quick. Earlier, we identified that they have two significant characteristics:
Marginal costs (resulting in high switching & multihoming costs)
Space constraints (resulting in high multihoming costs)
As we discussed, software doesn’t have marginal costs. The fact that you can copy and paste software at virtually zero cost has led us to a world of abundance where many things are free and infinitely available.
But what about space constraints?
Your initial reaction might be that software doesn’t have space constraints. We are talking about bits here, after all, not atoms. But if you look closely, you’ll notice that that’s not really true. Every layer in the stack has some sort of limited (pixel) real estate – and in a world of abundance, that scarce resource is extremely valuable.
Okay, back to the Google example.
If Google wants to become a default on the layer below the search engine, it must find and occupy limited real estate on the browser layer. There are billions of websites out there … but only one default: Your browser homepage.
Becoming the default browser homepage became Google’s actual moat. There can only be one homepage (no multihoming) and users are typically too lazy to change it (friction = switching costs).
As you well know, Google didn’t stop there. It moved down the stack and successfully conquered the browser layer with Google Chrome – which obviously shipped with Google Search as the default search engine. More importantly, it turned the address bar into a search box thereby melting the browser and the search engine into sort of one layer.
With Android – one of the most underrated acquisitions of all time – Google then moved even further down the stack. It now owns a significant chunk of the world’s most important base layer: the smartphone operating system. Unsurprisingly, Android ships with Chrome and Google Search pre-installed.
If you think about it, it’s kind of amazing that the largest operating system humanity has ever seen only exists to protect an advertising business two layers further up the stack.
Unluckily for Google, smartphone operating systems are not winner-take-all but winner-take-most markets. Not only does Apple have considerable market share in the smartphone market, its user base is significantly wealthier and thus more interesting to advertisers.
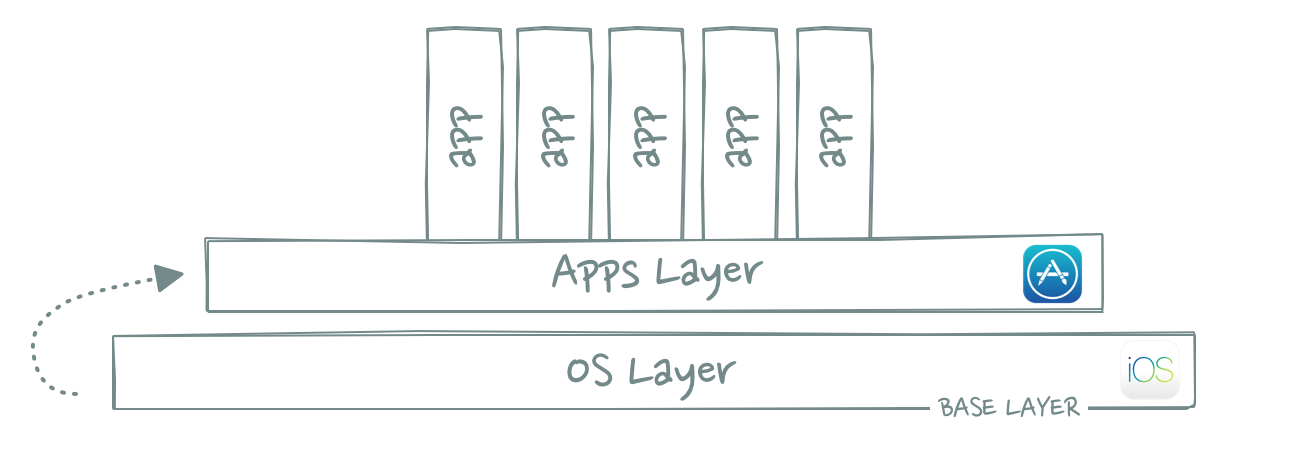
06 The Apple Stack
Apple is an interesting case study because its stack strategy has been so reciprocal to Google’s. It started with the base layer and then worked its way up the stack.
The first iPhone was released in 2007, but only in 2008 did the company launch the App Store. Opening up iOS to third-party developers created a new layer above the operating system: apps.
The apps layer is interesting because it created indirect network effects between developers and users, which added defensibility to the OS layer. That defensibility in turn meant that Apple was able to capture a lot of the value that was created on top of its platform. 30% to be exact.
30% value capture is great, but you know what’s even better? 100% value capture.
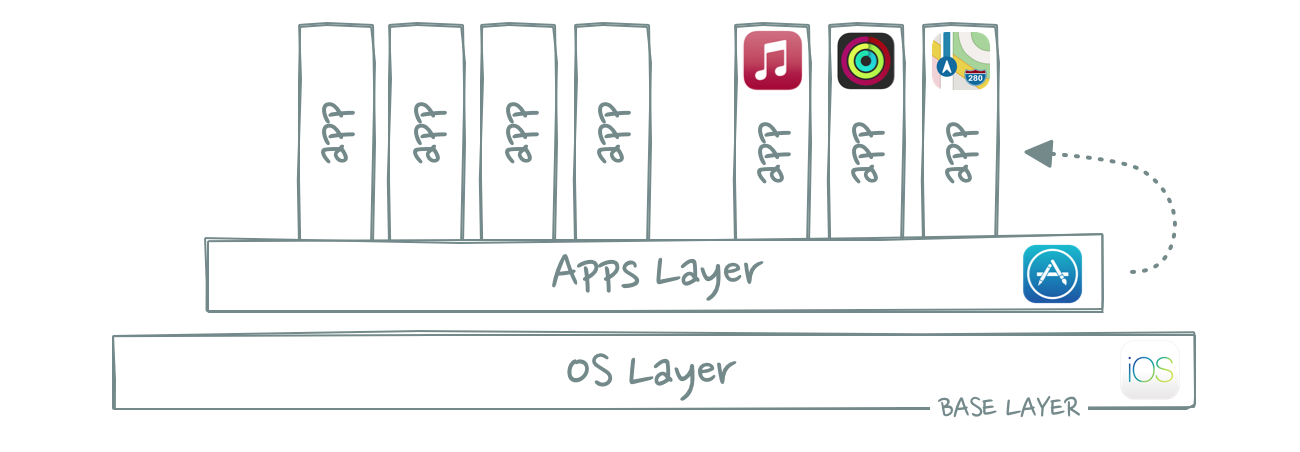
Over the last couple of years, Apple has increasingly launched and monetized its own apps (and services) on top of iOS. It has moved up the stack and is now competing with the third-party developers on its own platform.
Apple realized that it owns some of the most valuable pixel real estate in tech: The home screen. And the best way to monetize that real estate is by occupying as much as possible of it yourself.
The beautiful thing about defaults is that they beat almost any competing product – even if that competitor has strong network effects or is technically superior.
This is why Apple Maps has higher market share than Google Maps, why Apple Music is able to catch up with Spotify, and why Google pays Apple $15bn a year to remain the default search engine on Safari.
(I can already hear the Apple fan boys furiously typing. No, these apps aren’t pre-installed to create a better user experience. No, Apple Music is not a better product than Spotify. No, “privacy” is not a convincing argument that explains Apple Maps’ high market share.)
×××
It’s important to point out that not all of Apple’s default apps exist to increase value capture. That might be true for Apple News, Apple Arcade and Apple Fitness, but clearly not for apps like Maps or Health. So why do those exist?
Some of them add stickiness and switching costs to the iOS platform. iMessage, for example, creates network effects that make it harder for users to switch to a competing OS layer like Android.
Other default apps – like Maps – are solely there to mitigate risk from upper layer apps that might become too powerful. You’ll remember from the Google case study that Search became synonymous with the browser. And that the browser became the real operating system on desktop computers. That’s a scenario Apple wants to avoid at all cost. So instead of taking the risk that a service like Google Maps or Spotify becomes too dominant and threatens the base layer, Apple will launch its own (default!) maps and music apps.
This also explains why Apple doesn’t allow any competing app stores, browser apps (that aren’t built on WebKit) or game streaming services. Users are also not able to add 3rd-party apps to their iOS lock screen, change their default camera app or give quick access to a payment app other than Apple Pay. All of these limited real estate defaults are fully in Apple’s grip.
Apple Pay and Wallet are particularly important for Apple because they are tied to the user’s identity – which is another important layer in the stack.
07 The Identity Layer
So far, the layers we have looked at were all pretty distinct. The Google and Apple stacks we analyzed are simply different platforms and applications that build on top of each other. But not all layers are distinct pieces of software. Some layers are blurry and don’t have a clearly marked place in the hierarchy of the stack. One of those layers is the identity layer.
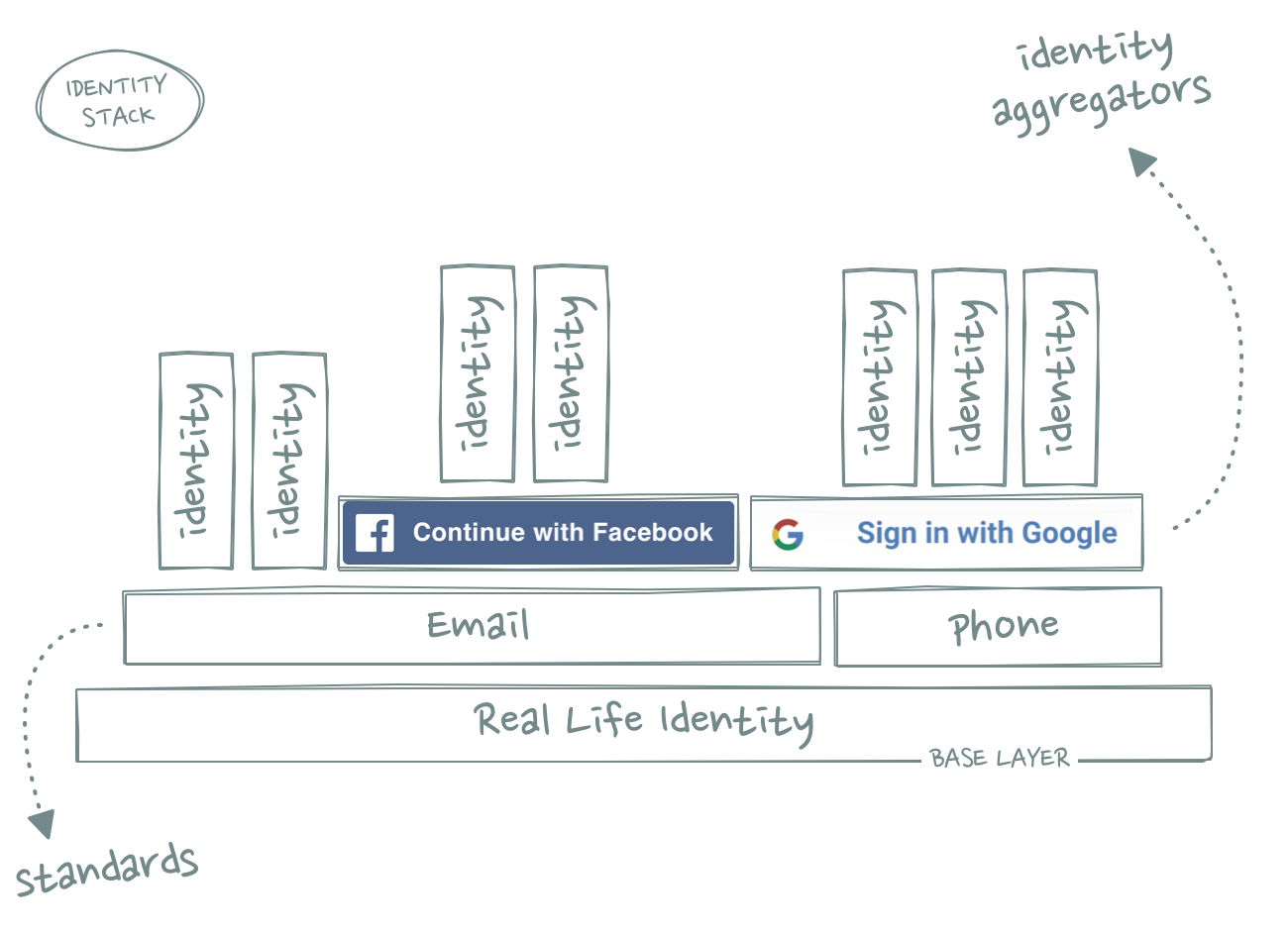
Earlier in this essay, we described the base layer of the stack as “the final interface between the stack and the end user”. Operating systems like iOS or Android are great examples because there are no other layers between the smartphone and the end user.
But what if the end of the stack isn’t an interface? What if the lowest possible layer in the stack is actually the user itself?
Identity is a crucial component of almost every single layer in the stack – especially if that layer is a network (which most layers are). Every network is just a collection of nodes and if you want to build connections between those nodes you need an identity layer. Even in a pseudonymous network, each user has a consistent identifier.
The fascinating thing about identity is that it’s kind of a stack of its own. When you sign up to a new app or service, you almost always use an existing identity. Until recently, that identity was typically your email address or phone number. Both email and phone numbers are great base layers for online identity because they are (sort of open) standards.
Unsurprisingly, in their attempts to become defaults, other companies have tried to create their own identity base layers. One of them is Facebook.
Facebook is a typical network effect business: The value to its users grows as a direct result of attracting more users. On top of the core social network there are several other network effect loops including Messenger (direct network effects), Newsfeed (data network effects) and Marketplace (indirect network effects).
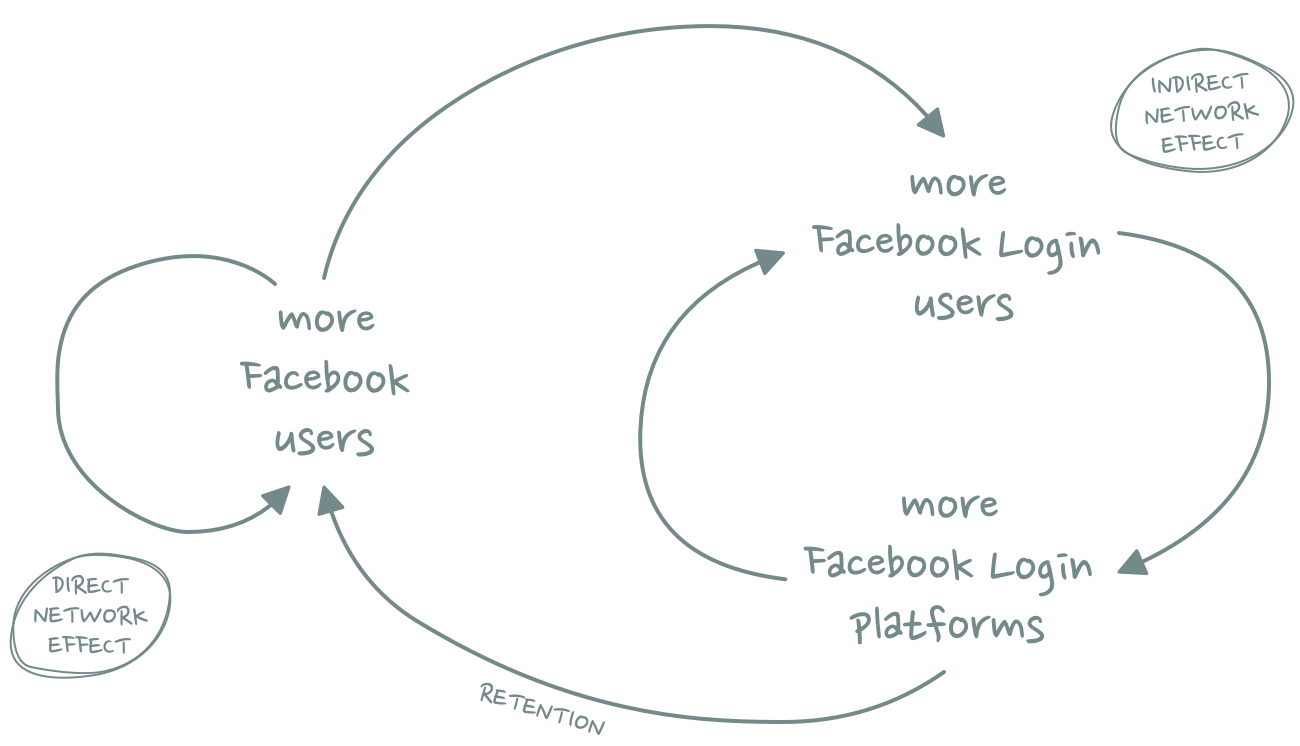
Facebook’s real stickiness, however, comes from another network effect. One that allowed the company to move a layer down the stack: Facebook Login
Facebook Login is a single sign-on service (SSO). It allows people to sign up to other social platforms and services using their Facebook account. SSO is more convenient for users and thus promises greater sign-up conversion rates for 3rd-party platforms. The more people use Facebook Login, the more platforms will offer it, thereby increasing the total number of accounts that a single user has connected to their Facebook identity.
As a result, it becomes really difficult *not* to use Facebook. In contrast to Google and Apple, Facebook doesn’t own an operating system and, thus, doesn’t enjoy the defensibility of a pre-installed default. But because Facebook is the de-facto online identity layer for so many people, it is almost guaranteed to secure some of that limited pixel real estate on the user’s home screen.
Unsurprisingly, Facebook is not the only company trying to become the default identity layer – dozens of companies are. Which brings us to the question of “winner-take-all-dynamics” and defensibility in the identity stack.
We started this essay with the observation that neither social networks nor messaging apps have tipped in favor of just one or two winning companies despite the strong network effect dynamics in these verticals. Interestingly, both of these product categories are also very closely tied to identity.
Instead of winner-take-all-dynamics, we are seeing not just multiple identity aggregators (SSO services) but – more importantly – many, many different identity networks building on top of them. When you sign up to a new social app using Facebook Login, your (pretended) identity in this new social app is most likely going to be distinct from your Facebook identity – which is probably the reason you are signing up to a new social service in the first place.
As I wrote in Is This Real Life?, identity is not monolithic but prismatic. Who you are on Facebook is different from who you pretend to be on TikTok. Your real name LinkedIn persona is not compatible with the pseudonymous identity you use on fringe Discord channels to shill shady new NFT projects. Google+ Circles and Facebook Lists always got this wrong: They let us change who we shared with, but not who we shared as.
As a result, we see intense multihoming in the online identity stack. There might be clear winners in certain verticals (e.g. LinkedIn for “professional networking”), but “social” as a whole is not a winner-take-all market.
That changes once we start to move down the stack and get closer to the base layer.
Like in previous examples, multihoming becomes less likely the closer we get to the world of atoms.
Your various different online identities on the top of the stack get bundled in a handful of identity aggregators. Most online services don’t offer more than three or four different SSO options because – you guessed it – there is limited pixel real estate in the sign-up flow.
Chances are you don’t actively use more than two different email addresses (one for work, one for personal life). Your phone number is directly tied to a physical device which makes multihoming unlikely because of the aforementioned multihoming costs and physical space constraints.
Once we get to the base layer of the stack – your real life identity – multihoming becomes virtually impossible. Unless you are Jason Bourne or suffer from severe schizophrenia, you only have one identity in real life.
The most interesting identity defaults to occupy are therefore all the interfaces between your real world identity and your digital self. For example, your driver’s license (see Apple Wallet), your payment details (see Apple Pay), or your medical records (see Apple Health).
All of these touchpoints represent sources of truth – which brings us to the last but most important kind of network effect default: Intersubjective realities.
It’s like “pics or it didn’t happen” but for sales people. A Salesforce entry is a timestamped proof point that a customer interaction or sales deal has actually taken place. It makes Salesforce an important source of company data. A system of record.
Salesforce is of course not the only available data source within a company. There are dozens of internal BI dashboards, spreadsheets and third-party software tools that track customer and revenue data. All of them are accurate in their own unique way, but they all tell you something slightly different.
A company can have multiple sources of data, but it can’t have multiple sources of truth. There is no multihoming on the truth layer. You need a *single* source of truth. A default.
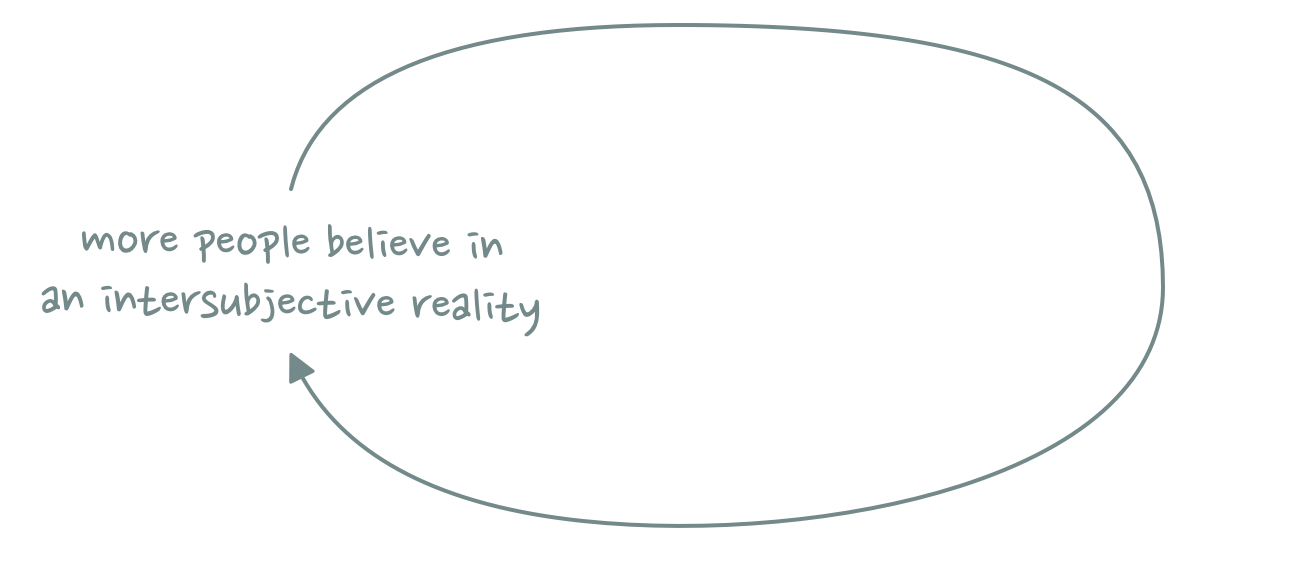
Salesforce is not more accurate than any of the other company data sources. It is not objectively better. But it becomes intersubjectively better if enough people agree that it should be the single source of truth.
“If it’s not in Salesforce, it doesn’t exist” is a reinforcing flywheel. A social network effect. The more people believe in it, the truer it becomes.
This is Salesforce’s core defensibility. You can replace a CRM system, but can you replace “the truth”?
×××
Intersubjective realities like being the default source of truth are not just intra-company network effects.
For many decades, a popular intersubjective reality was that “nobody ever got fired for buying IBM”. Salesforce feels like the 2021 version of that belief – and they are not the only company that fits that description.
I sometimes joke that every time I open Workday I’m reminded that we live in a simulation. Because getting to a $50bn+ valuation with a product as horrible as Workday’s is the best example we have of a glitch in the matrix.
Kidding aside, Workday’s real moat is, of course, the same as Salesforce’s and IBM’s. Nobody ever got fired for buying Workday. It’s the default HR tool of choice.
What’s so striking about these examples is the discrepancy between market cap and NPS score. It would be amazing if we lived in a world where companies with terrible UX did badly in the stock market, but that is clearly not the case. The fact that you can build a successful business without a truly great product is a real testament to how strong of a moat belief-based defaults really are.
Of course, intersubjective realities don’t just lead to suboptimal product defaults like Salesforce or Workday. These are just extreme edge cases to prove my point. Most of the default software products of today (think AWS, Stripe, Notion) became defaults because their products are just really good. But even great products need shared beliefs to become defaults.
Beliefs are the world’s most powerful network effects. They don’t just explain the success of software products. The price of Bitcoin, democracies and dictatorships, capitalism, and the power of the church are all based on intersubjective realities. No moat is more durable than a shared belief.
Jesus turned water into wine – but Salesforce turns shit into gold.
See, the real base layer of the stack isn’t an interface. And it’s not our identity either. It’s our collective minds.
Like other defaults we analyzed in this essay, intersubjective realities are able to capture a scarce piece of real estate. The most valuable real estate there is: Mind space.
09 Closing Thoughts
So where does this essay leave us?
Some people will say that I oversimplified some network effect concepts and that a couple of my arguments are pretty speculative.
They are not wrong.
I very deliberately downplayed the importance of certain network effects and took a few shortcuts to make the narrative work. But as I pointed out at the beginning, this post isn’t really about network effects. It’s about thinking in layers.
This essay doesn’t end with a definitive answer to the “Are network effects overrated?”-question, because there is none. Some are overrated. Some are underrated. Some are rated just right. It really depends on where in the stack you are.
Some people will say that this essay is a missed opportunity: “How can you write this essay without mentioning crypto even once?”
They are not wrong.
Decentralized protocols would make very interesting base layers and I’m particularly excited about web3 in the context of identity. Does crypto solve the problem of suboptimal defaults? Well, that’s a different question and I’m honestly not sure. Just because you have decentralized base layers doesn’t mean you won’t see centralization, aggregation and default rent seeking on top of them – no matter how you design them. Greed is like water: It always finds a way through.
I haven’t written about crypto in this essay because I’m still trying to wrap my head around it. It probably deserves a post of its own at some point.
Some people will say that intersubjective realities aren’t real network effects. They’ll say that I’m stretching the definition of network effects too far.
I think they are wrong.
I understand that the idea of social network effects is even more intangible and immeasurable than the already vague concept of “traditional” network effects – but it still surprises me how many people refuse to see beliefs as what they are. Not only do I think that beliefs are network effects, I think they are probably the most important and most defensible of them all. Perhaps this intersubjective reality just hasn’t reached its critical mass yet.
Some people will agree or disagree with other ideas in this essay. If you are one of them, I’d love to hear from you.
I set myself 24 goals for this year and completed 9 of them (38%), which is a significantly lower success rate compared to my 2019 and 2018 lists (60% and 56%, respectively).
Publish 52 blog posts ❌
This was my number one goal for this year and even though I ended up publishing only 39 posts, I managed to make writing a weekly habit. Starting to write on a regular basis has been one of best decisions I’ve ever made. Over the last 366 days, my essays have been read by more than 100,000 people, my Twitter follower base grew by more than 10x and I’ve met so many incredible and interesting people in the process. The internet is amazing.
█████ ██ ███████ ██ ███ ✅
Read 20 books ✅
Ended up reading 21 books. The Glass Hotel was the best fiction book I read this year, History Has Begun was my favorite non-fiction book.
Watch less TV ❌
I spent more than 160 hours watching TV this year – up more than 28% YoY. I blame the pandemic. And The Sopranos.
Swim a total distance of 120km ❌
Due to covid-19 I only managed to swim 72 kilometers this year.
Go for a swim at least once a week ❌
Back exercise every second day ✅
Did my exercises on 59.29% of all days.
██████ ████ ████ ❌
████████ ████ ❌
██ ████████████ ❌
Ship a redesign of this blog ❌
Still playing around with different mock-ups.
Finish work on my daily uniform ❌
Conduct a 2020 Quantified Self Project ✅
Publish my 2019 Quantified Self Report before end of Jan ❌
Didn’t find time to do this.
Limit meat consumption to 24 days ✅
No alcohol if I have to work the next day ✅
My beer consumption decreased by more than 69% and I had 13% less cocktails. I had a few more glasses of wine though (+31%)
Visit 1 country I haven’t been to before ❌
Explore more new places ✅
I measure this in form of Swarm check-ins at locations I haven’t been to before. My goal for this year was to make every 4th check-in a new place (25%). I ended up at a 26% rate.
Build a Personal CRM system ✅
While I didn’t do what I originally set out to do (building a CRM system myself), I found a pretty good solution in Clay, which does pretty much exactly what I was looking to build.
Keep phone screen time below 1h per day ❌
This was a way too ambitious goal.